字符表是由JVM中C++实现的HashTable结构(数组+链表)的字符串常量池,长度固定,不可扩容。数据结构如下图所示:
点击阅读详解Java的 StringTable
字符表是由JVM中C++实现的HashTable结构(数组+链表)的字符串常量池,长度固定,不可扩容。数据结构如下图所示:
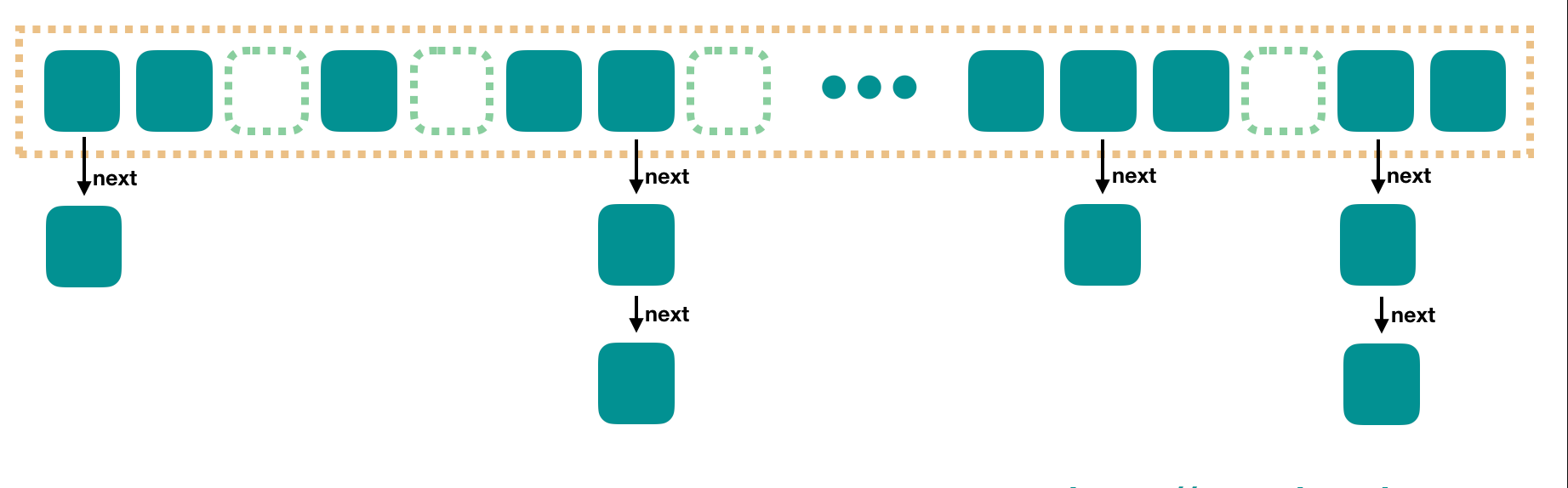
Java 6的Jvm中StringTabele是分配在永久代中,不会被GC,从Java 7开始StringTable迁移到heap堆内存中,会触发GC,Java 8完全移除了永久代的概念,并用MetaSpace替代。StringTable的不同的实现方案的细微不同之处,参考String.intern()章节。
StringTable源码解析
上文提到StringTable是数组+单向链表的结构。本小节,我们看一下StringTable源代码的几个核心方法。OpenJDK StringTable 源码
使用Handle string_or_null_h来摒弃GC导致字符串移动(对象地址变更)带来的问题。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
oop StringTable::do_intern(Handle string_or_null_h, const jchar* name,
int len, uintx hash, TRAPS) {
HandleMark hm(THREAD); // cleanup strings created
Handle string_h;
if (!string_or_null_h.is_null()) {
string_h = string_or_null_h;
} else {
string_h = java_lang_String::create_from_unicode(name, len, CHECK_NULL);
}
assert(java_lang_String::equals(string_h(), name, len),
"string must be properly initialized");
assert(len == java_lang_String::length(string_h()), "Must be same length");
// Notify deduplication support that the string is being interned. A string
// must never be deduplicated after it has been interned. Doing so interferes
// with compiler optimizations done on e.g. interned string literals.
if (StringDedup::is_enabled()) {
StringDedup::notify_intern(string_h());
}
StringTableLookupOop lookup(THREAD, hash, string_h);
StringTableGet stg(THREAD);
bool rehash_warning;
do {
// Callers have already looked up the String using the jchar* name, so just go to add.
WeakHandle wh(_oop_storage, string_h);
// The hash table takes ownership of the WeakHandle, even if it's not inserted.
if (_local_table->insert(THREAD, lookup, wh, &rehash_warning)) {
update_needs_rehash(rehash_warning);
return wh.resolve();
}
// In case another thread did a concurrent add, return value already in the table.
// This could fail if the String got gc'ed concurrently, so loop back until success.
if (_local_table->get(THREAD, lookup, stg, &rehash_warning)) {
update_needs_rehash(rehash_warning);
return stg.get_res_oop();
}
} while(true);
}
由于无法动态扩容,所以当链表平均长度超过2时,会进行rehash,通过重新计算hash值让字符串分布更均匀。具体的源代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
// Rehash
bool StringTable::do_rehash() {
if (!_local_table->is_safepoint_safe()) {
return false;
}
// We use current size, not max size.
size_t new_size = _local_table->get_size_log2(Thread::current());
StringTableHash* new_table = new StringTableHash(new_size, END_SIZE, REHASH_LEN, true);
// Use alt hash from now on
_alt_hash = true;
if (!_local_table->try_move_nodes_to(Thread::current(), new_table)) {
_alt_hash = false;
delete new_table;
return false;
}
// free old table
delete _local_table;
_local_table = new_table;
return true;
}
void StringTable::rehash_table() {
static bool rehashed = false;
log_debug(stringtable)("Table imbalanced, rehashing called.");
// Grow instead of rehash.
if (get_load_factor() > PREF_AVG_LIST_LEN &&
!_local_table->is_max_size_reached()) {
log_debug(stringtable)("Choosing growing over rehashing.");
trigger_concurrent_work();
_needs_rehashing = false;
return;
}
// Already rehashed.
if (rehashed) {
log_warning(stringtable)("Rehashing already done, still long lists.");
trigger_concurrent_work();
_needs_rehashing = false;
return;
}
_alt_hash_seed = AltHashing::compute_seed();
{
if (do_rehash()) {
rehashed = true;
} else {
log_info(stringtable)("Resizes in progress rehashing skipped.");
}
}
_needs_rehashing = false;
}
这个时候有同学可能就会问了,为什么采用rehash的方式而不是像HashMap一样转为红黑树呢?
首先红黑树是理论上上性能最优解,完全可以通过合理规划和使用,避免HashTable性能退化到这个地步,StringTable的设计初衷也是这样的。对于一般的情况,rehash已经可以满足对性能的要求。第三点,维护链表和红黑树互转的业务代码较过于复杂,维护成本更高,没有必要。
String.intern()方法
Java的String有一个名为 intern() 的公共方法,用户可以通过调用此方法主动将字符串添加到StringTable中。
当调用intern方法时,首先检查StringTable中是否已经存在,已经存在则直接返回StringTable中的引用。当StringTable中不存在时, 实现方案会有些许不同。
Java 6,不存在时,将字符串复制一份,插入到StringTable中 Java 7及后续的版本,不存在时,将当前字符串的引用,插入到StringTable中。
举个栗子🌰:
1
2
3
4
var var0 = new String("hello ") + new String("world");
String intern = var0.intern();
var var1 = "hello world";
assert intern == var1; // Java 6不相同
1
2
3
var var0 = new String("hello ") + new String("world");
var var1 = "hello world";
assert var0.intern() == var1;
两段相同的代码在不同的JDK版本中执行,结果会有有些许的不同。Java 8可以正常执行,但是Java 6会抛出断言错误异常。
其他风险及注意事项
合理的规划和使用intern可以减少堆内存的使用,合理的使用可以显著的提高内存的利用率。与之相对的,滥用或者错误的使用intern()方法,由于StringTable的桶数量固定,当数据远远超过桶的数量时(2-3倍以上),导致链表的长度过长,查询效率退化为O(n),最终反而影响程序的执行性能。
线上事故案例分享: 前两年同事开发的一个项目,数据写入DB之前,会用到jackson进行序列化转为json字符串,用户的唯一ID做为json的字段名使用。问题的发现过程也比较简单,上线之后这个进程不定期的隔几天时间就会出现频繁的Full GC,再发展就会发生OOM并宕机。jmap把内存dump下来之后发现字符串数量明显异常,经过一系列的排查,最终定位为大量的用户唯一ID字符串在内存中没有被GC掉。在深入的排查发现是jackson库的默认启用intern对象的字段名。数以千万计的用户唯一ID,再内存中无法被GC掉,至此也就破案了。
常见的json框架(e.g. jsckson, fastjson .etc)都会默认开启并使用intern方法,利用此特性对json对象的字段名进行常量化管理,减少内存占用,提高内存利用率。但是基本上都或多或少的出现过导致内存泄露的案例。使用前需要谨慎评估,是否业务场景可以用intern方法?依赖的第三方库是否有默认使用?。例如:国家名,地区名,类对象字段名称等重复使用率高的字符,完全可以使用intern来避免每个用户单独占用内存。
Jackson: JsonParser.Feature.INTERN_FIELD_NAMES Fastjson: Feature.InternFieldNames
JVM 启动参数
-XX:StringTableSize=65536
通过修改启动参数可以调整字符表桶数量。JDK 11之后hashtable的数组长度缺省值为65535,之前版本的JVM默认值为60013,有些更老的版本时1009.
-XX:+PrintStringTableStatistics 打印字符表统计信息, 帮助排查问题。线上环境不建议开启
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
SymbolTable statistics:
Number of buckets : 32768 = 262144 bytes, each 8
Number of entries : 129215 = 2067440 bytes, each 16
Number of literals : 129215 = 7173248 bytes, avg 55.514
Total footprsize_t : = 9502832 bytes
Average bucket size : 3.943
Variance of bucket size : 3.990
Std. dev. of bucket size: 1.998
Maximum bucket size : 14
StringTable statistics:
Number of buckets : 65536 = 524288 bytes, each 8
Number of entries : 23470 = 375520 bytes, each 16
Number of literals : 23470 = 2157736 bytes, avg 91.936
Total footprsize_t : = 3057544 bytes
Average bucket size : 0.358
Variance of bucket size : 0.361
Std. dev. of bucket size: 0.601
Maximum bucket size : 5
-XX:+UseStringDeduplication
G1GC引入的一个减少重复字符串的垃圾回收特性。Shenandoah GC于JDK 11支持。截至JDK 17 LTS发布,ZGC仍不支持此特性(JDK 18开始支持)。
-XX:StringDeduplicationAgeThreshold=3. 默认经历3次GC,字符串将被纳入去重的候选对象。设置过大可能会导致YGC时间增长。
还有一系列相关的参数:
- -XX:StringDeduplicationTargetTableLoad=7.000000
- -XX:StringDeduplicationShrinkTableLoad=1.000000
- -XX:-StringDeduplicationResizeALot
- -XX:StringDeduplicationInitialTableSize=500
- -XX:StringDeduplicationHashSeed=0
- -XX:StringDeduplicationGrowTableLoad=14.000000
- -XX:StringDeduplicationCleanupDeadPercent=5
- -XX:StringDeduplicationCleanupDeadMinimum=100
-XX:+CompactStrings
默认开启压缩字符串. 当字符串能够使用latin-1(ISO-8859-1)编码描述时,优先使用latin-1(ISO-8859-1)编码。相比于UTF-16编码,节省50%内存。 与此同时,由于内存占用的减少,字符串拼接,字符串复制等等方面也有显著的性能提升(复制的数据少)。
-XX:+OptimizeStringConcat
默认开启优化字符串串联连接操作。编译阶段优化字符串的串联方式,精简优化生成的字节码。
参考资料
- VM Options Explorer - Oracle JDK17
- Performance evaluation of Java garbage collectors for large heap transaction based applications
- 深入浅出 String.intern ()
- 深入解析String#intern

本作品采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可。欢迎转载、使用、重新发布,但务必保留文章署名 TinyZ Zzh (包含链接: https://tinyzzh.github.io ),不得用于商业目的,基于本文修改后的作品务必以相同的许可发布。 如有任何疑问,请 与我联系 (tinyzzh815@gmail.com) 。

评论